
If you have built a RAG (Retrieval-Augmented Generation) system, you have likely faced the “Lost in the Middle” problem.
You ask your AI a question. It retrieves 10 documents. But the one document that actually contains the answer is buried at position #7. The LLM gets distracted by the noise in documents #1–6 and gives you a hallucinated answer.
How do you fix this? You need a better way to sort.
Enter Cross-Encoder Reranking. It is the “Quality Control” layer that turns a good search engine into a great one.
Today, we break down what it is, how it differs from standard retrieval, and why it is the secret sauce for high-accuracy AI.
The Problem: Speed vs. Understanding
To understand Cross-Encoders, we first have to look at the standard way we search, which uses Bi-Encoders (Vector Search).
Bi-Encoders are built for speed. They turn your query into a list of numbers (a vector) and compare it to millions of documents instantly. But to be that fast, they have to be a little superficial. They look at the general “vibe” of the document, not the exact relationship between every word.
Real World Analogy: The Resume Screener vs. The Interview
- Bi-Encoder (The Resume Screener): Imagine a recruiter with a stack of 1,000 resumes. They scan them in 5 seconds each, looking for keywords like “Python” or “Marketing.” It’s fast, but they might accidentally throw away a great candidate just because the resume was formatted weirdly.
- Cross-Encoder (The Interview): This is when you bring the top 10 candidates into a room and talk to them for an hour. You listen to every word they say in context of your specific questions. It’s slow—you can’t interview 1,000 people—but it is incredibly accurate.
How Cross-Encoders Work
A Cross-Encoder is a deep learning model that processes the Query and the Document simultaneously.
Unlike a Bi-Encoder, which processes them separately (in parallel), a Cross-Encoder feeds both into the neural network at the same time. This allows the “Self-Attention” mechanism to look at how every single word in the query relates to every single word in the document.
It can spot subtle nuances like negation (“not happy”), direction (“Paris to London” vs “London to Paris”), and specific instructions that vector search often misses.
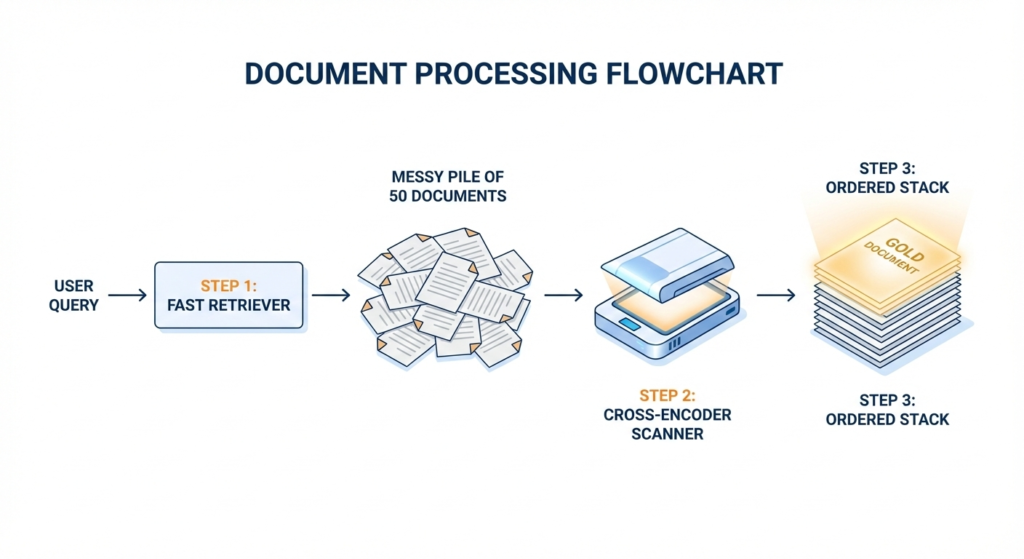
The “Two-Stage” Pipeline
Because Cross-Encoders are slow (computational heavy), you cannot use them to search your entire database. You use them only for the final polish.
This is called Two-Stage Retrieval:
- Stage 1 (Retrieval): Use a fast Bi-Encoder to find the top 50 roughly relevant documents out of 1 million.
- Stage 2 (Reranking): Use a precise Cross-Encoder to deeply analyze those 50 documents and sort them so the best one is at the very top.
Why This Matters for RAG
In a RAG system, your LLM has a limited “Context Window” (memory). If you feed it trash, it produces trash.
By adding a Reranker:
- Higher Accuracy: You ensure the LLM sees the correct fact first.
- Less Hallucination: You can filter out irrelevant documents that might confuse the model.
- Efficiency: You can send fewer documents to the LLM (saving money) because you are confident the top 3 are excellent.
Summary
- Bi-Encoders are for Retrieval (Fast, Broad).
- Cross-Encoders are for Reranking (Slow, Precise).
- Using them together gives you the speed of Google with the understanding of a human expert.
If your AI application is struggling with accuracy, don’t just buy a bigger LLM. Try adding a Cross-Encoder Reranker. It’s often the highest ROI upgrade you can make.