
When you type a prompt into ChatGPT, you might think the AI is reading your words just like a human would. It isn’t.
Computers cannot inherently understand language; they only understand math. Before an AI can process your request, your text must be chopped up, converted into numbers, and fed into the neural network.
This chopping process is called Tokenization. And the specific, smart way modern AI does this chopping is often called Byte Pair Encoding (BPE).
Today, we look at how AI turns Shakespeare into spreadsheets.
What is Tokenization?
At its simplest, tokenization is the act of breaking a long string of text into smaller units called “tokens.”
If you don’t tokenize, the computer just sees a massive, meaningless blob of characters. It needs distinct units to analyze.
Real World Analogy: The Mosaic Artist Imagine you want to build a picture (a sentence) using colored tiles. You cannot just pour a bucket of paint on the floor. You need discrete tiles.
Tokenization is the process of breaking your image down into those individual tiles so you can arrange them. Sometimes a tile is a whole object (a “word”), and sometimes it’s just a tiny speck of color (a “character”).
The “Goldilocks” Problem
When scientists first started building AI, they struggled to decide how big the tiles should be.
- Character Level (Too Small): You break “Apple” into
A,p,p,l,e.- Problem: It takes way too much computing power to process simple sentences because the sequences are so long. The AI struggles to “see” the meaning of the whole word.
- Word Level (Too Big): You keep “Apple” as one unit.
- Problem: The English language has hundreds of thousands of words. If the AI encounters a new word like “crypto-currency” that wasn’t in its training dictionary, it crashes or labels it as “Unknown.”
We needed a middle ground. A “Goldilocks” solution. That solution is BPE (Byte Pair Encoding).
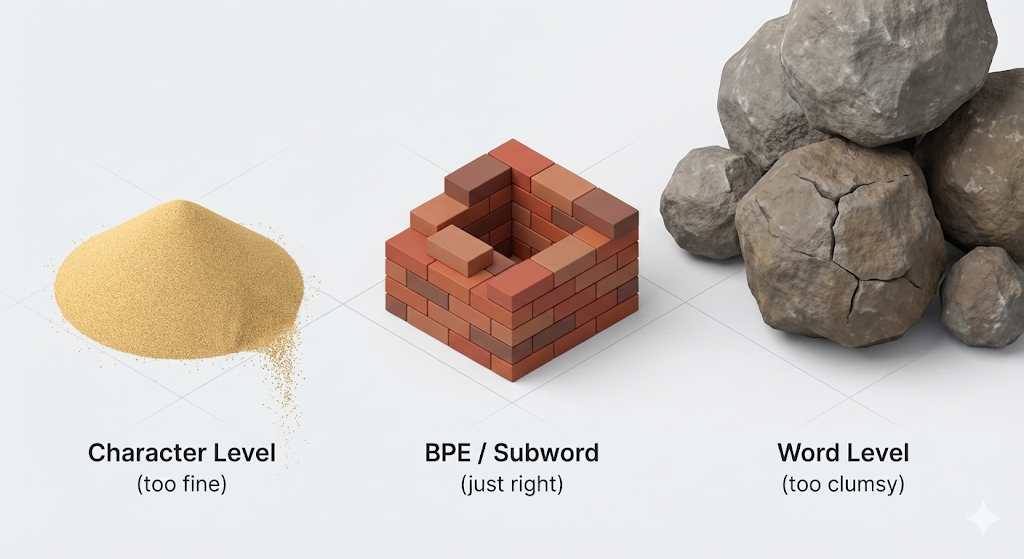
Enter BPE: The “Subword” Revolution
Byte Pair Encoding is a form of Subword Tokenization.
Instead of memorizing every single word in the universe, BPE looks for common patterns or chunks of characters that appear frequently.
It starts with individual letters and iteratively merges the most common pairs.
- It sees “t” and “h” together often, so it creates a token
th. - It sees
thandetogether often, so it creates a tokenthe. - It sees
i,n,goften, so it creates a tokening.
This allows the AI to be incredibly efficient. Common words like “the” become a single token. Rare words are built from multiple smaller tokens.
Real World Analogy: The LEGO Master Builder
- Character Level: You build a castle using only tiny 1×1 stud bricks. It takes forever and is fragile.
- Word Level: You try to buy a pre-molded plastic castle. It’s easy, but if you want to change the tower, you can’t. You are stuck with that specific shape.
- BPE (The Solution): You use specialized LEGO pieces. You have a standard 2×4 brick, a “window” piece, and a “roof” piece.
With BPE, if the AI sees the word “Unfriendly”, it doesn’t need to memorize a new definition. It recognizes the LEGO pieces:
Un(not) +friend(person) +ly(adjective characteristic).By combining these known sub-parts, it instantly understands a word it has never seen before.
Why BPE is Critical for Modern AI
The beauty of BPE is its flexibility. It solves the “Unknown Word” problem.
If you invent a new word today, like “ChatGPThusiast”, a word-based model would fail. A BPE model handles it effortlessly by tokenizing it into familiar chunks: Chat + GPT + hus + iast.
This is why LLMs are so good at coding, German (which loves compound words), and medical terminology. They don’t memorize dictionaries; they understand the components of language.
Summary
Before an AI can “think,” it must “read.”
- Tokenization is breaking text into data pieces.
- BPE is the smart strategy of breaking text into meaningful sub-parts (like prefixes, roots, and suffixes) rather than just letters or whole words.
It is the ultimate efficiency hack, allowing AI to understand infinite variations of language with a finite vocabulary.